Measuring Internet Links: Accessing the Common Crawl Dataset Using EMR and Pyspark in AWS
This article aims to inform the reader about a massive dataset that can be accessed using Amazon’s AWS.
In this tutorial, I am going to show you how to access the Common Crawl dataset using an AWS account. The Common Crawl is a non profit that archives the entire Internet every 2 months. They started crawling the Internet in 2013 and each time they crawl and store roughly 200 terabytes of data with metadata about 2–3 billion web pages each time. According to their website: “Web crawl data can provide an immensely rich corpus for scientific research, technological advancement, and innovative new businesses.”
The common crawl provides access to WARC files in a columnar format using Apache Parquet on AWS. You can access the dataset by starting an EMR cluster that runs Apache Spark. All of the data is available on S3 using the following link: s3://commoncrawl/cc-index/table/cc-main/warc/. By modifying the link parameters, one can access different data crawls.
Steps to Run Spark Queries on Common Crawl in AWS:
Step 1: You must launch an AWS EMR cluster running the latest release and have Spark enabled.

Step 2: After the cluster is launched, navigate the notebooks section of Amazon EMR and configure the notebook to run Pyspark.

Step 3: Import Spark using the following import statement

Step 4: Run a Spark query and save to a dataframe with desired parameters. (You can modify the input bucket by selecting a different available web crawl in the dataset.) You can then run any customized SQL query to gain insights.
input_bucket = 's3://commoncrawl/cc-index/table/cc-main/warc/crawl=CC-MAIN-2020-16/'
df = spark.read.parquet(input_bucket)
df.createOrReplaceTempView("urls")
sqlDF = spark.sql("SELECT COUNT(*) as URLCount FROM urls")
sqlDF.show()Your output will look like this:

Results and Insights:
Query 1:
First, let’s see what the most popular top level domains on the Internet are. We run the following SQL query:
sqlDF = spark.sql("""SELECT url_host_tld AS Top_Level_Domain, COUNT(*) AS Number_Of_Pages, COUNT(DISTINCT url_host_name) AS Number_Of_Hosts, COUNT(DISTINCT url_host_registered_domain) AS Number_Of_Domains
FROM urls
GROUP BY url_host_tld
ORDER BY Number_Of_Pages DESC""")
sqlDF.show()
.Com is king. In the latest crawl, we see 1.5 billion .com pages. Next is .org with 193 million pages. Internet popularity in Russia has risen with 157 million domains listed.
Query 2: Most Popular .com domains
Next, we want to see what the most popular .com domains are in the latest crawl.
sqlDF = spark.sql("""SELECT COUNT(*) AS count, url_host_registered_domain
FROM urls
WHERE url_host_tld = 'com'
GROUP BY url_host_registered_domain
HAVING (COUNT(*) >= 100)
ORDER BY count desc""")
sqlDF.show()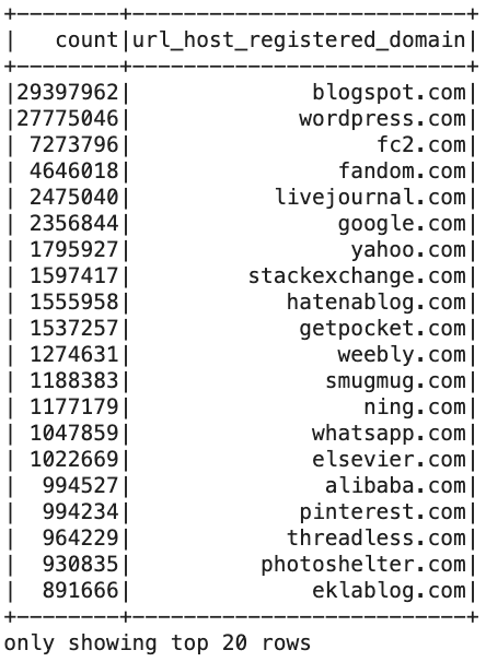
Here, we wee blogspot.com being the most popular, showing us how big blogging still is. Next, we see wordpress.com and fc2.com taking #2 and #3. We see a good mix of information sites alongside photo or message sharing websites in the top 20.
Query 3: Most Popular .org domains
Finally, we want to see what the most popular .org domains are, which is the second most common top level domain. We run the query:
sqlDF = spark.sql("""SELECT COUNT(*) AS count, url_host_registered_domain
FROM urls
WHERE url_host_tld = 'org'
GROUP BY url_host_registered_domain
HAVING (COUNT(*) >= 100)
ORDER BY count DESC""")
sqlDF.show()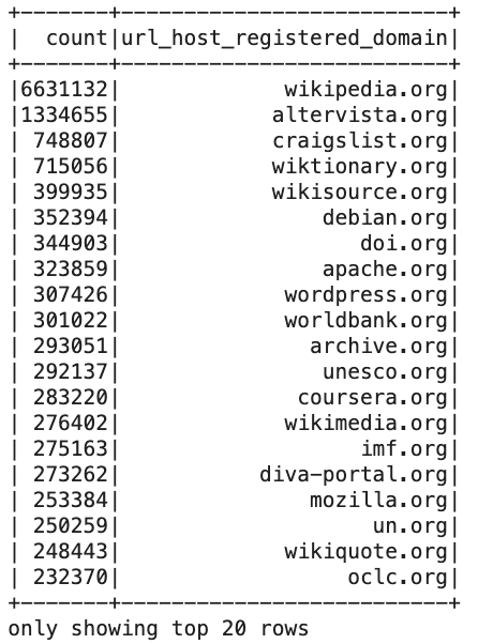
Wikipedia, everyone’s favorite online encyclopedia comes in #1 with the most number of domains with over 6 million. Most of the top 20 is made up of software-related domains like debian.org or apache.org and there are also many global organizations like worldbank.org and imf.org.
Conclusions:
I hope to draw awareness to the Common Crawl dataset and encourage people to check out their website https://commoncrawl.org/. If you have access to AWS, it is a great dataset to query using EMR and Jupyter. Also, if you have any interesting use cases, feel free to reach out to me, and I would love to discuss it and potentially participate.
-By Basil Latif
Connect with me on social media:
LinkedIn: https://www.linkedin.com/in/basil-latif/
Twitter: https://twitter.com/bazill_theG
